Running MySQL/MariaDB at scale (2)
Scaling Technologies
As we defined different types or “dimensions” of database scaling, let’s now look into the technologies available for the MySQL and MariaDB RDBMS. This is where it gets complicated. Unfortunately, there isn’t a single solution that fits all needs. Instead, there are many solutions that solve different scaling problems. MySQL was originally designed as a single-server system. A MySQL or MariaDB server is not per se aware of other servers, nor a cluster, as it was not designed as a distributed system. Servers must be configured and additional software may have to be installed in order to operate MySQL or MariaDB in a network cluster. The resulting architecture is probably better described as a multi-server system than a distributed system. So, let’s state an important conclusion right away. If you have a requirement for a distributed database system and you are not bound by legacy MySQL databases, other products probably fit the bill better. Today, there are not just NoSQL database systems offering seamless horizontal scaling, but there is a growing number of relational RDBMS under the umbrella term “NewSQL” which provide conventional SQL APIs with transactional capabilities and painless scalability.
That being said, if you are somehow stuck with MySQL or MariaDB, you still have good options to grow your system. Let’s begin with simple solutions and then move on to more complex ones.

Master-slave replication is a feature which is built into both MySQL and MariaDB. As such it is the easiest to set up. No third party software is required. Only the individual nodes must be configured for replication. You can start a slave by loading a dump/backup of the master database into it and enabling the MySQL replication and binary log features. Conceptually, master-slave replication is like cloning or mirroring a single-server to one or more connected servers. The entire database system is duplicated in near realtime whenever the master is updated. This happens asynchronously, which means that the slave nodes receive updates with a very slight delay. The master server writes all changes to a binary log (binlog), which is then read by and applied to the slave servers. The typical use cases for this setup are read scale out and some degree of high-availability. The slave nodes can only be used for reading, because updates to the slave nodes are not replicated. If an application writes a record to a table on a slave node, this may cause an index or row id collision in which case the duplicate is not consistent any longer.
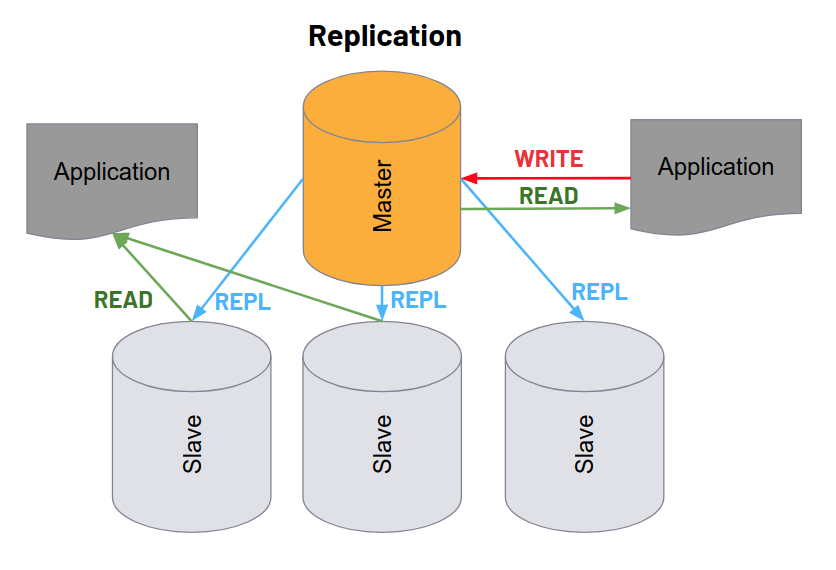
Despite these drawbacks, master-slave replication is useful in certain scenarios. For example, you could configure a slave node to deal with heavy analytic loads when you don’t want data analysis to affect the main production server. Or you could use it as a failover. If the main system dies for some reason, then the slave will become the new master. With proper configuration, this crossover process is automatic. Let’s just say that the crossover itself is not always failsafe, which means (1) there is some amount of data loss between failure detection and crossover completion and (2) the automatic crossover can fail for various reasons and require manual intervention. Hence, the degree of high availability you get from master-slave replication is not what you might expect. Alternative topologies such as ring replication or star replication can be configured with master-slave replication. In theory, these topologies offer write scalability, because updates are propagated from all nodes. However, because there is no collision detection and because you have to use replication filtering, these topologies are quite brittle, complex and rarely used in practice. Also, master-slave replication does not address size scale out at all.
What is the next best thing, then? As for high availability and read scalability, the answer is probably Galera cluster. Galera is a third-party library which is available for both MySQL and MariaDB. Unlike master-slave replication, Galera is a multi-master system. This means that every node in a Galera cluster behaves like a master and can be written to. You can perform updates, inserts and DDL statements on any node in a Galera cluster and these changes are then automatically propagated to all other nodes. Updates happen synchronously, which means that updates to one node are instantaneously applied to the cluster. An update operation is only complete when it has been propagated to all other live nodes. This implies that applications can even perform read/write operations on different nodes and still maintain consistency. Conceptually, a Galera cluster therefore behaves like one single “super server”. This has three advantages: (1) the fact that there is a cluster rather than a single server is hidden from the applications, (2) there is no crossover process; any malfunctioning node is simply ejected from the cluster and the remaining nodes take over, (3) the symmetrical architecture is ideal for load-balancing. You can use almost any load-balancing strategy to optimise performance and minimise the impact of failing nodes.
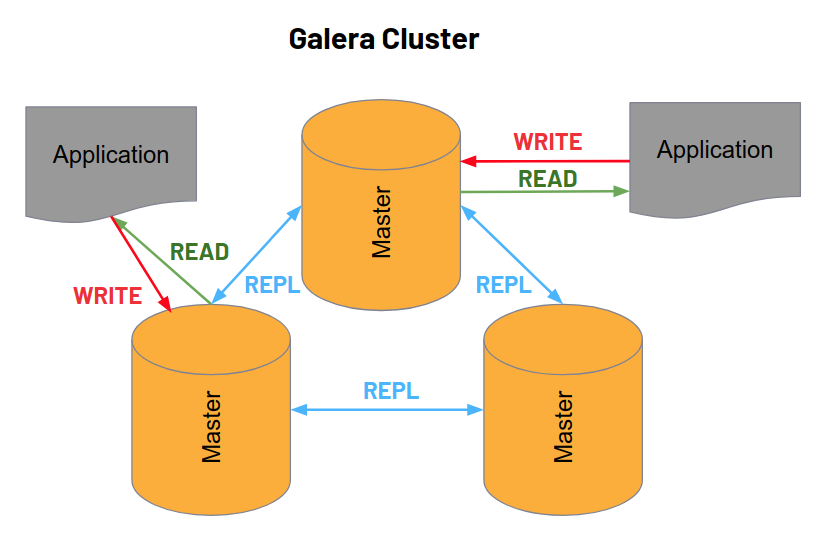
While Galera is a good solution for high-availability, there are also downsides. One obvious one results directly from its synchronous architecture: while read scale out is theoretically infinite, write scaling is not. In fact, write operations are slower, because data has to be propagated to all nodes upon every update. Because write scale out is a bottleneck, Galera is not the ideal choice for high-traffic OLTP. Another drawback is that Galera only works with the InnoDB storage engine, which imposes limitations to size scaling as we shall see. Another issue is that table locking isn’t fully supported. Also, auto-increment values (row ids) are interleaved between nodes and therefore not strictly sequential anymore. This may cause issues if applications assume that ids are generated sequentially in time. Another problem I came across in my daily work with Galera is that large transactions can cause the binlogs to increase dramatically in size. In one case, it grew to multiple hundred Gigabytes and exhausted the disk space on one particular node. This in turn caused the node to become unresponsive, yet it wasn’t ejected from the cluster, which is probably worst-case scenario. Despite these issues, Galera is a good choice for HA if write load scaling is of no concern.
Now let’s look into size scaling. What options do you have if your data is growing larger? We have previously stated as a rule of thumb, that MySQL performance begins to degrade when tables reach a size of multiple Gigabytes. Certain operations are bound to become slow on such large tables. But that’s not the end of the line. With both MariaDB and MySQL, you have the option to partition tables horizontally (across rows). What this means is that tables are split into different physical and logical units, whereas the partition structure is largely transparent to applications, which is to say that applications do not need to know about it. Physically, a partitioned table is no longer stored in a single file. It is stored in multiple files that correspond to the logical distribution of its data. These files can spread over different disks and/or file systems. Logically, a partition is defined either by a hash key for random distribution, or by range, value lists, or time intervals. For example, if you have a large customer database with customers in different states, you could create a list partitioned table with one partition for each state. Or, if you have a large table with time series data you could define time intervals for partitioning and even assign the busiest partitions to a fast SSD.
The main advantage of partitioning is that it speeds up query performance, especially if the partition keys are cleverly chosen. Obviously, it is faster to read an index or row data of a single small partition than of an entire table. Another advantage is that it allows tables and databases to grow fairly large. We’re talking multiple terabytes range. Partitioning is a built-in feature and constitutes part of the CREATE TABLE syntax. It can be combined with the above mentioned HA and read scaling technologies, including Galera. However, there are also disadvantages. Partitioning does not provide infinite size scale, because clearly there is a limit to how much disk space a single server can hold. Replicating large capacity servers for HA is also fairly expensive. Another limitation is that partitions are static. To add, delete, or reorganise partitions, you have to execute ALTER TABLE statements. These are known to be very slow on InnoDB databases, especially if the table is large. Altering table structure or re-partitioning large tables is therefore likely to involve downtime due to locking. If you have to avoid downtime, you would have to resort to some type of blue-green deployment making the update process even more painful.
Again, partitioning is not the end of the line in size scaling. If your MySQL database is so large that only a multitude of servers can hold it, you are moving into the realm of a distributed database system. The method of splitting logical datasets into chunks that exist on different physical nodes in a cluster is called sharding. Shards are the units that correspond to partitions except that they are spread over the entire cluster network. The original MySQL/MariaDB storage engines cannot handle this requirement. You have to use a different storage engine as well as clustering software to achieve this. There are two popular choices: the Spider storage engine, available for both MySQL and MariaDB and the NDB storage engine plus MySQL Cluster. The latter is only available for MySQL. These systems are quite different, both in their design and intended use cases. Spider is basically a storage engine that provides access to remote tables and partitions located on other nodes. You have to configure connection and partitioning information on the Spider node and Spider presents them to the application as if they were located on the same server. Spider supports cross-shard joins and cross-shard XA transactions. Data nodes commonly use the InnoDB storage engine, but they can also use Aria or any other MySQL storage engine. So basically, Spider acts like a proxy/router that ties together a number of cluster nodes.
The Spider storage engine is great for providing access to huge databases that contain terabytes upon terabytes of data. In addition, it permits read and write load scaling as the actual read/write operations are handled by the data nodes. It has weaknesses, though. First, because the configuration is static, there is no intrinsic mechanism for dealing with dynamically growing databases. The sharding would have to be manually reorganised each time the database grows. Second, it does not provide high-availability by and of itself. Though it is possible to use replication for HA on the data nodes, the Spider head node introduces a new single point of failure. Making both spider nodes and data nodes highly available is very complex. This HA issue is addressed by the competing NDB (network database) engine which promises triple-nine availability comparable to Galera. NDB with MySQL cluster also offers auto-sharding. The system distributes shards automatically and transparently across nodes. As the database size grows, nodes can be added to the cluster and the system automatically rebalances the existing shards. This functionality is more akin to the distributed database systems we find in the NoSQL and NewSQL categories.
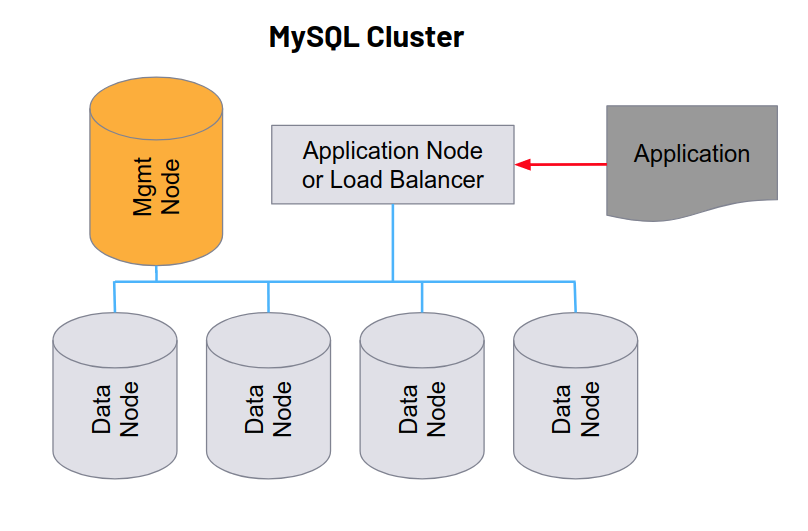
High availability is achieved by maintaining shard replicas on different nodes. If one node fails, the other replica(s) can still be accessed. Like Galera, MySQL Cluster performs synchronous updates whereas an update is considered complete if at least two replicas are persisted. Another specialty of MySQL Cluster/NDB is that it provides hybrid storage which means that a part of the data, by default all indexed columns, are kept in memory. This allows high data throughput and very fast query performance which is not possible to achieve with Spider. On the downside, it consumes a lot of memory so that the RAM requirements for data nodes are rather high. Internally, NDB uses memory-intensive T-Trees to store indexes. Therefore, with NDB you have to consider indexing carefully. An NDB cluster can be load-balanced flexibly, just like Galera, because transactions are always consistent across all nodes. It’s internal structure is somewhat more complicated, however. In addition to data nodes, a MySQL cluster has two specialised nodes: a management node which is in charge of cluster control, configuration and management and an application node, which is the endpoint for application access, so to speak. The latter is optional and can be left away in favour of load-balancing data nodes directly. The management node is required, however. It should be set up redundantly in order to avoid introducing a single point of failure.