Running MySQL/MariaDB at scale (3)
TiDB Scaling Alternative
It may sound contradictory, but one of the best choices for scaling MySQL/MariaDB is not to use MySQL/MariaDB at all. I mentioned that MySQL was originally designed as a single server system. Unfortunately, this architecture makes horizontal scaling challenging. We looked at different scaling options in the last section and it turned out that the only choice for a true distributed MySQL system is currently NDB with MySQL Cluster. However, NDB/MySQL Cluster is very resource-intensive and it also happens to be difficult to install and configure. There is an interesting alternative. It’s called “TiDB“ and it’s developed by the Chinese-American company PingCap. The product is open-sourced and available under the Apache license. TiDB promises MySQL compatibility and horizontal scalability for both OLAP and OLTP workloads. It is one of many contemporary NewSQL implementation based on the original Google Spanner and HBase designs. To my knowledge, it’s the only one that offers MySQL compatibility. Recently, I’ve had the privilege to perform tests, benchmarks and performance comparisons with a TiDB cluster over a period of several weeks. I found the results were quite impressive.

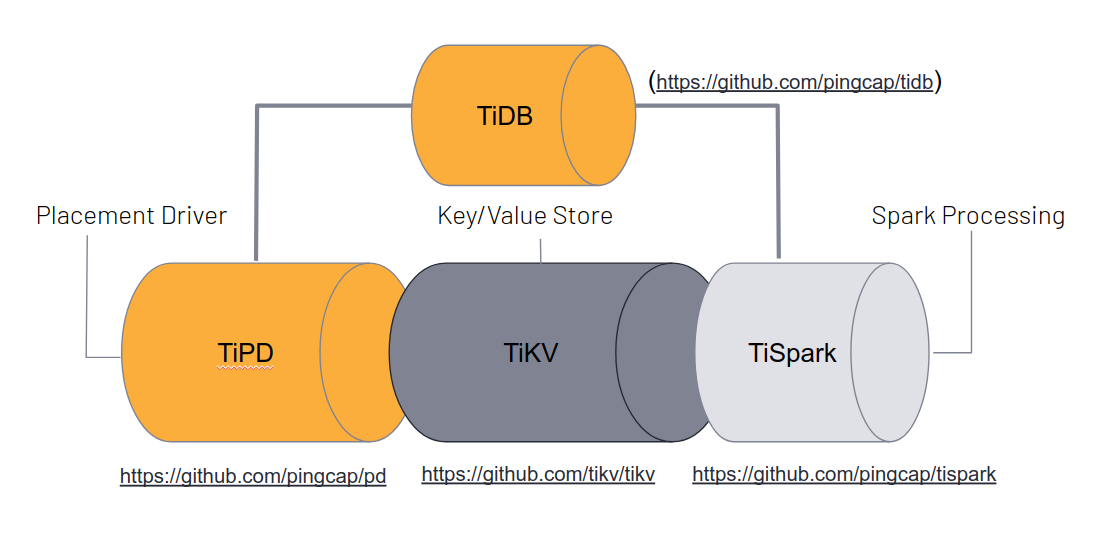
In brief, the characteristics of TiDB are as follows: it natively “speaks” the MySQL protocol, so your applications can connect to the database using your existing MySQL driver/clients. It is also MySQL syntax-compatible, so there is a good chance that your existing MySQL queries can be run against TiDB without change. There are a few edge cases and feature differences, which I will explain later. Unlike MySQL, TiDB is a true distributed system, which means that it automatically distributes storage as well as query execution across the cluster. This implies three important characteristics: auto-sharding and balancing, parallel query execution on different machines, and distributed replicas (by default three) for high availability. The TiDB architecture consists of at least three different components: a TiDB component that speaks SQL and constitutes the endpoint for your application; a PD component that performs cluster management functions; and a TiKV component that performs storage and retrieval operations. All of these components are typically deployed redundantly for high availability and can be load-balanced to provide a single point of access.
In addition, TiDB comes with two optional components: Prometheus/Grafana for monitoring and alerting plus TiSpark for connecting the database to Apache Spark stream processing in an efficient manner, for example for big data analytics. TSpark directly talks to the TiKV storage engine without going through the TiDB component. As the name implies, TiKV is a key value storage engine. Technically, it is a thin layer on top of the well-known RocksDB storage engine, which also powers many other database products, including (optionally) MySQL and MariaDB. Based on this architecture, TiDB offers three ways a access data: through traditional SQL queries, through Apache Spark, and through a high-performance low-level key value API. Furthermore, TiDB provides distributed transactions with strong consistency, based on either pessimistic or optimistic models. Transactions are ACID-compliant with some differences to the ANSI and MySQL isolation levels. So in layman terms, with TiDB you get a scalable and highly-available database which is syntax compatible with MySQL and behaves in many ways like a traditional MySQL server.
TiDB
- Manages outside connections
- Receives SQL requests and returns results
- Processes SQL logic, serialises SQL data <--> key value
- Computes query results
- Locates the TiKV address for storing and computing data
- Exchanges data with TiKV
- No data storage, computing only
PD
- Provides cluster management based the Raft consensus algorithm
- Provides automatic sharding and replication
- Stores metadata of the cluster such as the region location of keys
- Schedules and load balances regions in the TiKV cluster
- including but not limited to data migration and Raft group leader transfer
- Allocates the transaction ID that is globally unique and monotonically increasing
TiKV
- Responsible for persistence operations
- Provides key-value store API with distributed transactions
- Snapshot isolation for consistent distributed (ACID) transactions
- Supports geo replication and coprocessors
- Uses RocksDB internally
- Can be used stand-alone or with TiDB
But make no mistake about it, TiDB is a different animal. First and foremost, it is designed for big data. Unless your database processes terabytes of data and/or thousands of transactions per second, you won’t gain very much from TiDB. In fact you might lose some performance when running queries on small data sets, because a distributed system introduces network latency. However, if you have reached the limits of the single server architecture and struggle with massive data and/or workloads, then give TiDB a try. Parallelisation and easy scale out are the areas where TiDB really shines. Probably the best way to get acquainted with TiDB is to download the “playground” version via tiup on a local machine. This script installs a docker-based local cluster that is up and ready for test runs in minutes. For a more involved test run, there are different deployment methods to choose from: Ansible or tiup for bare metal installations, or TiDB Operator for Kubernetes installations. All three methods include lifecycle management. Alternatively, there is an SaaS cloud service available from PingCap with elastic scaling based on either AWS or Google Cloud. TiDB isn’t difficult to install though. Installation-wise, I had experienced more awkwardness with certain MySQL technologies than with TiDB.
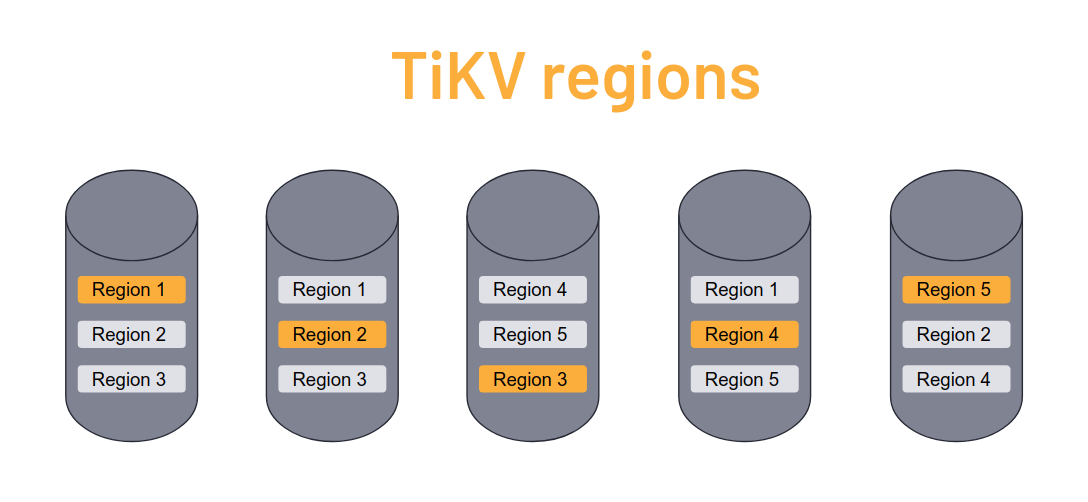
The way sharding works in TiDB is quite interesting. The storage layer of TiDB splits up data into so-called regions, which are small (approx. 100MB) large chunks of data containing ranges of key value pairs. Multiple contiguous regions compose the data is a logically represented as a table. High availability is accomplished by maintaining multiple copies of each region across different cluster nodes. When a storage node is added to the cluster, regions are automatically rebalanced so that data is equally distributed across nodes. When a node is dies or is taken down, the missing region replicas are automatically replaced onto other nodes. When a query is executed, the cluster first determines which regions need to be accessed and then optimises read/write operations accordingly. The region metadata is managed by the PD component with etcd providing fast and reliable metadata storage. It is natural that the information in tables grows during the database lifetime. Thus when a table grows, TiDB simply adds more regions. Some dynamic tables may grow and shrink. When regions themselves grow too large, they are split into two regions with adjacent ranges. Conversely, when data shrinks and regions become too small, they are merged by TiDB.
Let’s have a brief look at MySQL compatibility. As mentioned, TiDB is fully compatible with the protocol of MySQL 5.7 and its most common features and syntax. However, there are notable exceptions. For example, neither stored procedures nor user defined functions are currently supported by TiDB. Another common feature that is missing from TiDB are foreign key constraints, because these cannot be implemented efficiently in a distributed database. Consequently, either the application, the API, or middleware must replace the functionality provided by stored procedures, UDFs and constraints. One example would be maintaining relational integrity. Unsupported MySQL syntax elements such as foreign key constraints, storage engine specifications and such are parsed but ignored by TiDB. Another important feature is the AUTO_INCREMENT column attribute, which is often used for primary keys. AUTO_INCREMENT columns are supported by TiDB, however, there are some minor differences. When running multiple TiDB endpoints, the AUTO_INCREMENT value is only guaranteed to be monotonic and unique but not sequential any longer. Moreover, explicit assignment of AUTO_INCREMENT values may break uniqueness and lead to conflicts. TiDB features the “mysql” metadata table and all operations that can be performed on it, including user management. The “performance_schema” metadata table is also present, however, it is a dummy data structure which always provides empty values as TiDB uses Prometheus and Grafana for performance monitoring.
Unsupported features
- Stored procedures
- Triggers
- Events
- Add/drop primary key
- User-defined functions
- FOREIGN KEY constraints
- FULLTEXT functions
- SPATIAL functions
- Table locks (get_lock and release_lock)
- Character sets other than utf8, utf8mb4, ascii, latin1 and binary
- Non-binary collations
- SYS schema
- Optimizer trace
- XML Functions
- X-Protocol
- Savepoints
- Column-level privileges
- CHECK TABLE syntax
- CHECKSUM TABLE syntax
- CREATE TABLE tblName AS SELECT stmt syntax
- CREATE TEMPORARY TABLE syntax
- XA syntax
TiDB supports most SQL modes we know from MySQL/MariaDB, including the compatibility SQL mode. It should be noted that TiDB’s default SQL mode differs from MySQL/MariaDB’s default mode. You might want to adjust this before testing queries against TiDB. Most of the ecosystem tools available for MySQL/MariaDB also work with TiDB. You can continue to use SQLYog, Workbench, DBeaver or whatever IDE you prefer. Mysqldump also works fine with TiDB, however, it is rather slow for large amounts of data. You could use the LOAD DATA statement or the MyLoader tool for data import instead, or TiDB’s very own TiDB Lightning tool which offers superior data ingestion rates. For more complex scenarios, for example for migrating an always-on OLTP system or online data from multiple servers, TiDB offers a data migration tool (DM). Data migration with DM is based on a two step process. First, historical and static data is imported with one of the tools described above. In the second step, data is synchronised using MySQL/MariaDB replication. To that end, the DM master reads MySQL binlogs and replicates the data in near realtime onto the TiDB cluster. The schema routing and binlog event filtering features enable fine grained control over data structures and the import process.
Finally, the reverse is also possible. You can replicate data from a running TiDB cluster to a downstream system in two ways. One is replication via binlog as described in the previous section of this article. The TiDB binlog tool provides replication from TiDB to a MySQL/MariaDB slave. Alternatively, there is TiCDC component for more involved replication use cases. TiCDC can replicate to a number of different backends, such as Apache Kafka, Apache Pulsar for stream processing, MySQL, MariaDB or any protocol-compatible slave. TiCDC sits directly above the TiKV storage layer, so transactions are replicated even if they are not SQL transactions. While you can use replication and mysqldump as backup methods, TiDB also comes with its own backup tool. The new TiDB 4.x “dumpling” tool is a replacement for mysqldump and mydumper. It offers superior speed and extended features, such as file splitting and dump-to-cloud. Alternatively, another tool called “BR” for “backup and restore” can be used create efficient backups of single tables to network attached storage, such as a NFS server.
More information about TiDB is available at PingCap’s website: docs.pingcap.com.